Unlike SQL which operates on sets, Cypher predominantly works on sub-graphs.
The relational equivalent is the current set of tuples being evaluated during a SELECT query.
The shape of the sub-graph is specified in the MATCH clause.
The MATCH clause is analogous to the JOIN in SQL. A normal a→b relationship is an
inner join between nodes a and b — both sides have to have at least one match, or nothing is returned.
We’ll start with a simple example, where we find all email addresses that are connected to the person “Anakin”. This is an ordinary one-to-many relationship.
SQL Query.
SELECT "Email".* FROM "Person" JOIN "Email" ON "Person".id = "Email".person_id WHERE "Person".name = 'Anakin'
| ADDRESS | COMMENT | PERSON_ID |
|---|---|---|
| 2 rows | ||
|
|
|
|
|
|
Cypher Query.
START person=node:Person(name = 'Anakin') MATCH person-[:email]->email RETURN email
| 2 rows |
|---|
|
|
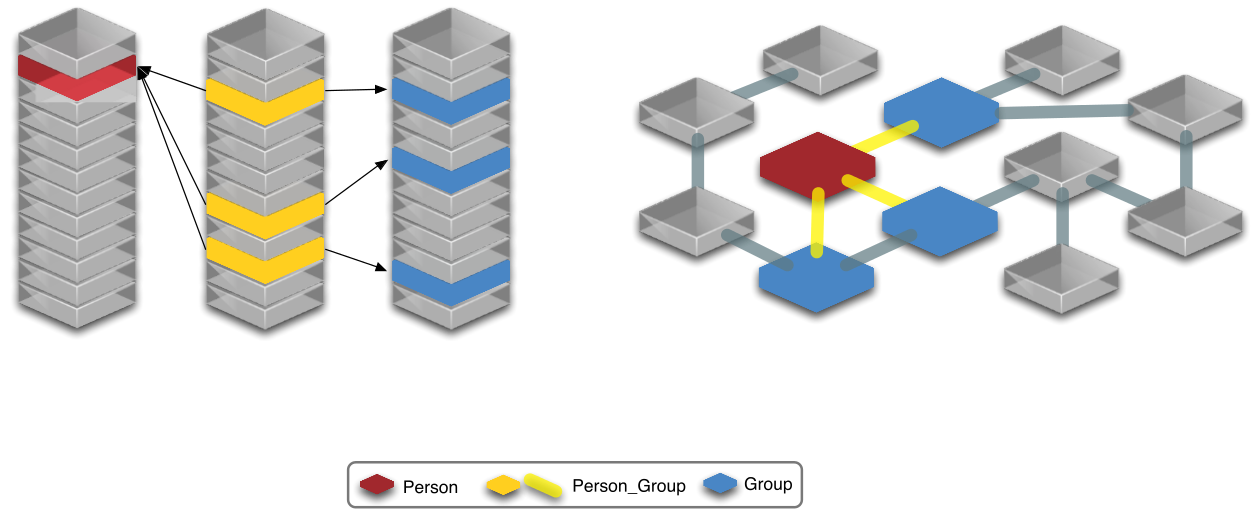
There is no join table here, but if one is necessary the next example will show how to do that, writing the pattern relationship like so:
-[r:belongs_to]-> will introduce (the equivalent of) join table available as the variable r.
In reality this is a named relationship in Cypher, so we’re saying “join Person to Group via belongs_to.”
To illustrate this, consider this image, comparing the SQL model and Neo4j/Cypher.
And here are example queries:
SQL Query.
SELECT "Group".*, "Person_Group".* FROM "Person" JOIN "Person_Group" ON "Person".id = "Person_Group".person_id JOIN "Group" ON "Person_Group".Group_id="Group".id WHERE "Person".name = 'Bridget'
| NAME | ID | BELONGS_TO_GROUP_ID | PERSON_ID | GROUP_ID |
|---|---|---|---|---|
| 1 rows | ||||
|
|
|
|
|
Cypher Query.
START person=node:Person(name = 'Bridget') MATCH person-[r:belongs_to]->group RETURN group, r
| group | r |
|---|---|
| 1 row | |
|
|
An outer join is just as easy.
Add OPTIONAL before the match and it’s an optional relationship between nodes — the outer join of Cypher.
Whether it’s a left outer join, or a right outer join is defined by which side of the pattern has a starting point. This example is a left outer join, because the bound node is on the left side:
SQL Query.
SELECT "Person".name, "Email".address FROM "Person" LEFT JOIN "Email" ON "Person".id = "Email".person_id
| NAME | ADDRESS |
|---|---|
| 3 rows | |
|
|
|
|
|
|
Cypher Query.
START person=node:Person('name: *')
OPTIONAL MATCH person-[:email]->email
RETURN person.name, email.address
| person.name | email.address |
|---|---|
| 3 rows | |
|
|
|
|
|
|
Relationships in Neo4j are first class citizens — it’s like the SQL tables are pre-joined with each other. So, naturally, Cypher is designed to be able to handle highly connected data easily.
One such domain is tree structures — anyone that has tried storing tree structures in SQL knows that you have to work hard to get around the limitations of the relational model. There are even books on the subject.
To find all the groups and sub-groups that Bridget belongs to, this query is enough in Cypher:
Cypher Query.
START person=node:Person('name: Bridget')
MATCH person-[:belongs_to*]->group
RETURN person.name, group.name
| person.name | group.name |
|---|---|
| 3 rows | |
|
|
|
|
|
|
The * after the relationship type means that there can be multiple hops across belongs_to relationships between group and user.
Some SQL dialects have recursive abilities, that allow the expression of queries like this, but you may have a hard time wrapping your head around those.
Expressing something like this in SQL is hugely impractical if not practically impossible.